By Xelera Technologies · Benchmarked on the Blackcore® ACE 3100-TS+
In high-frequency trading, every microsecond can be the difference between a winning and a losing strategy. Gradient Boosting Tree models, LightGBM, XGBoost, CatBoost, are now deeply embedded in that critical path: scoring market signals, detecting anomalies, ranking order flow. And most inference frameworks weren’t designed for the latency requirements that entails.
But raw speed is only half the problem. In a live trading system, an inference call that usually completes in 2 µs but occasionally takes hundreds µs is unreliable. Unpredictable tail latency translates directly into missed executions, degraded fill rates, and unquantifiable risk exposure. What HFT infrastructure demands is not just low latency, but deterministic latency: a guarantee that the system responds within a known bound, every single time.
Xelera Silva was built for exactly this. It is a turnkey solution for deterministic, microsecond-level GBT inference that requires no FPGA expertise and no low-level software engineering on your side. You bring your trained model. Silva handles the rest.
Today, we are expanding it with a new complementary deployment flavour, and publishing the benchmark data to back it up.
The Original Silva: FPGA Acceleration and the Determinism Guarantee
Silva’s existing execution mode offloads inference to an AMD Alveo FPGA accelerator card. Dedicated silicon executes tree traversal in a way no general-purpose CPU can match for medium-to-large models, and because the FPGA runs each inference request on its own dedicated hardware resources, its latency profile remains uniquely stable under concurrent load.
The key concept is dedicated execution. When multiple trading strategies run simultaneously on the same hardware, a CPU-based solution must arbitrate shared resources: caches, memory bandwidth, execution units. That contention does not show up in median latency. It shows up in the tail. The 99th percentile climbs. Maximum spikes appear. And in a trading system, those spikes are the number that matters, because the worst case determines whether an order makes it to market in time.
The FPGA sidesteps this entirely. Each inference request runs on hardware resources dedicated to that task, which no other process can touch or compete for. Whether the server is running 1 strategy or 15, the FPGA’s execution time is governed by the model and the clock. That is what makes it deterministic: the tail does not grow, the spikes do not appear, and the 99th percentile stays within a few hundred nanoseconds of the median.
But leveraging FPGA accelerator card comes with a physical cost: data must travel over PCIe from the host to the card and back. For large models where compute dominates, that round-trip is negligible relative to the inference time. For small, fast models that fit comfortably in the CPU cache, the PCIe overhead becomes the bottleneck.
That is the gap we set out to close.
Introducing Xelera Silva CPU-Only
The new CPU-only flavour of Silva runs inference on the host processor using highly optimised CPU code. There is no accelerator card, no PCIe transfer, no round-trip latency. Small models stay entirely within the CPU cache, which means the data is already where the compute needs it to be.
The result is a new performance regime for small GBT models: sub-microsecond inference latency at the 99th percentile.
Because it is pure software, it also runs on any machine, premises and cloud. It requires no FPGA card, no specialised hardware, and no infrastructure provisioning beyond an isolated CPU core. If your environment can run a Linux process, it can run Xelera Silva.
The Benchmark: Blackcore® ACE 3100-TS+ with AMD Alveo U50
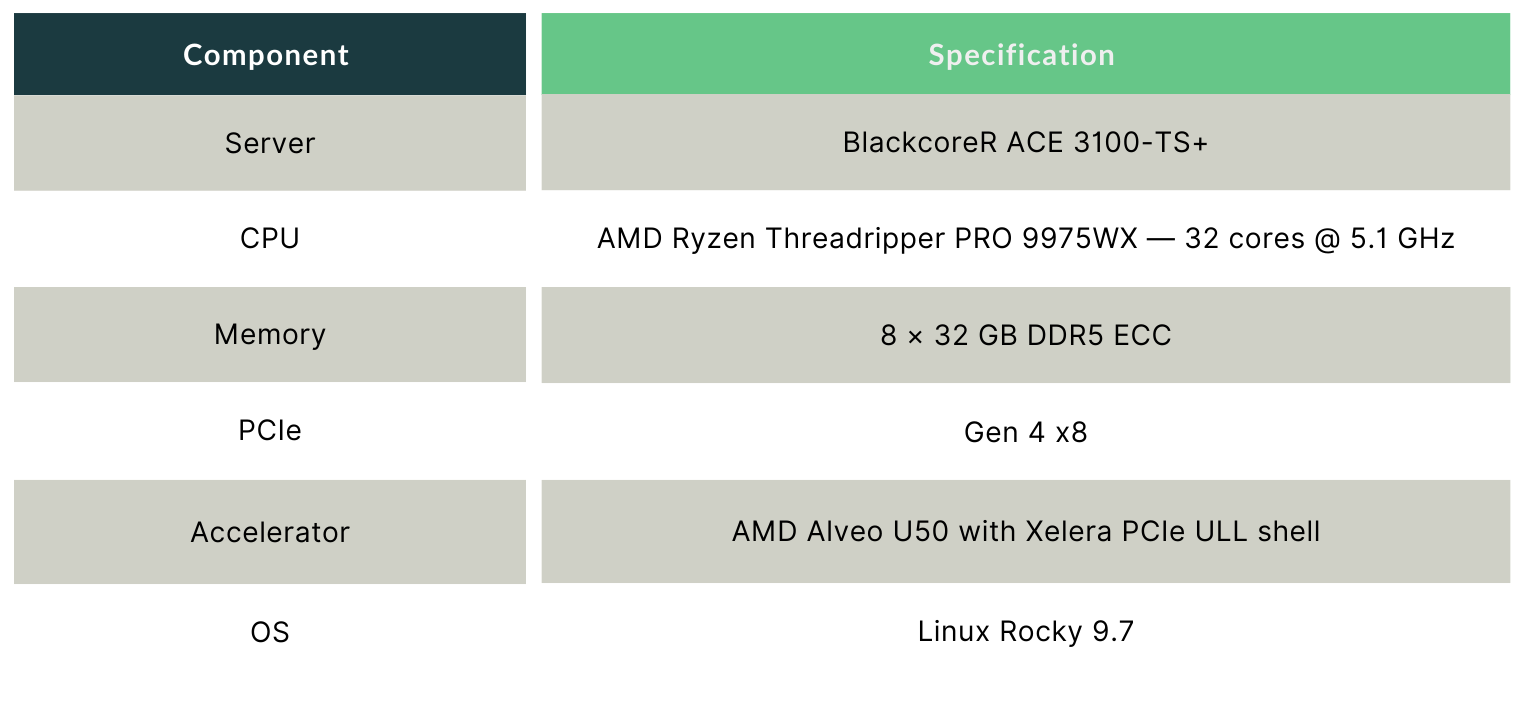
To validate both execution modes under controlled, production-representative conditions, we ran a comprehensive benchmark on the Blackcore® ACE 3100-TS+ server, a high-performance platform built for latency-sensitive workloads, equipped with an AMD Alveo U50 PCIe FPGA accelerator.
Test Platform
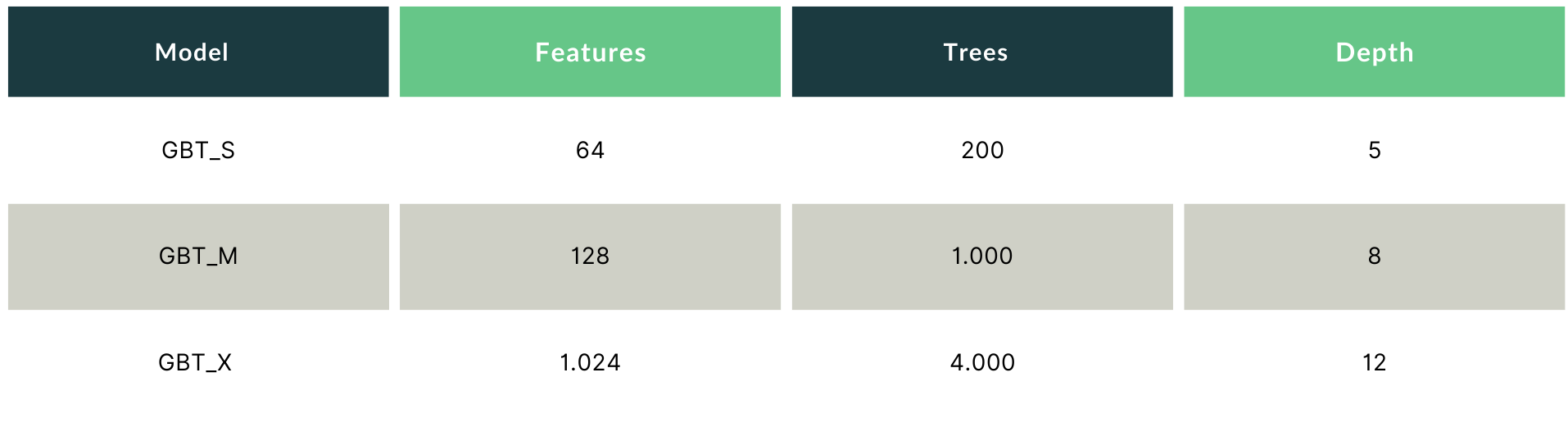
Model Configuration
All latency measurements are roundtrip at the API interface, batch size 1, over 1,000,000 repeated inferences on an isolated CPU core. Three software configurations are compared:
• intel_oneDAL_sw: Intel oneDAL 2024.5.0, CPU-optimised baseline
• xl_silva_sw: Xelera Silva CPU-only (new)
• xl_silva_acc: Xelera Silva FPGA-accelerated (existing)
Results: Single-Model Inference
GBT_S — Where CPU-Only Wins
For the GBT_S model (64 features, 200 trees), Silva CPU-only is the fastest path, beating even the FPGA-accelerated mode, because the PCIe round-trip overhead outweighs the accelerator’s compute advantage at this model size.
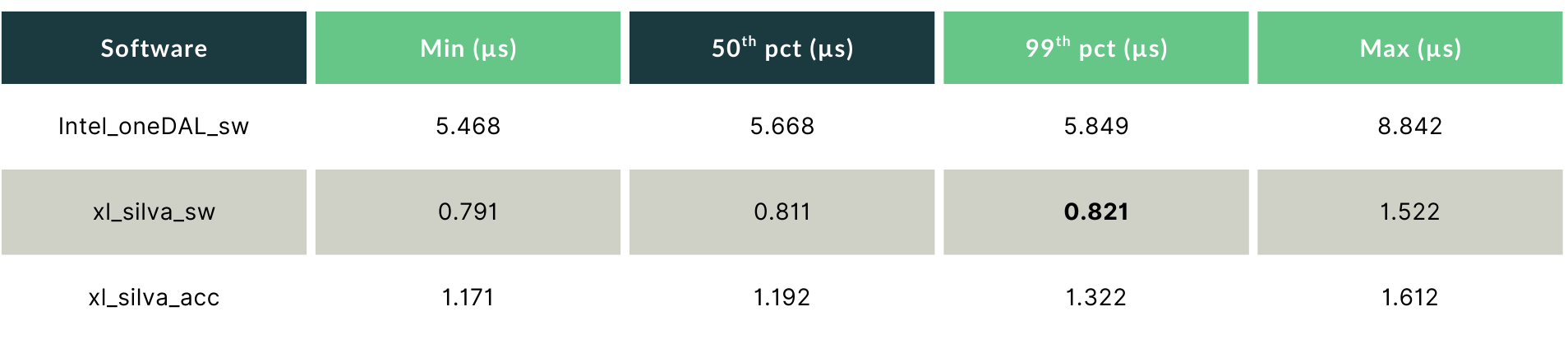
xl_silva_sw delivers a 99th percentile of 0.821 µs, 7.1× lower than Intel oneDAL, and faster than xl_silva_acc by 0.5 µs. The min-to-99th spread is just 30 nanoseconds, indicating an exceptionally tight, near-deterministic distribution. In the absence of PCIe overhead, the CPU cache keeps inference times consistent enough that tail behaviour approaches what you would expect from dedicated hardware.
For HFT teams running small, fast models on the critical execution path, this result is significant: you can achieve sub-microsecond, near-deterministic tail latency on hardware you already own, with no accelerator card required.
GBT_M — Where the Accelerator Takes Over
As model complexity grows, the physics shift. For GBT_M (128 features, 1,000 trees), the FPGA’s compute advantage decisively outweighs the PCIe overhead.
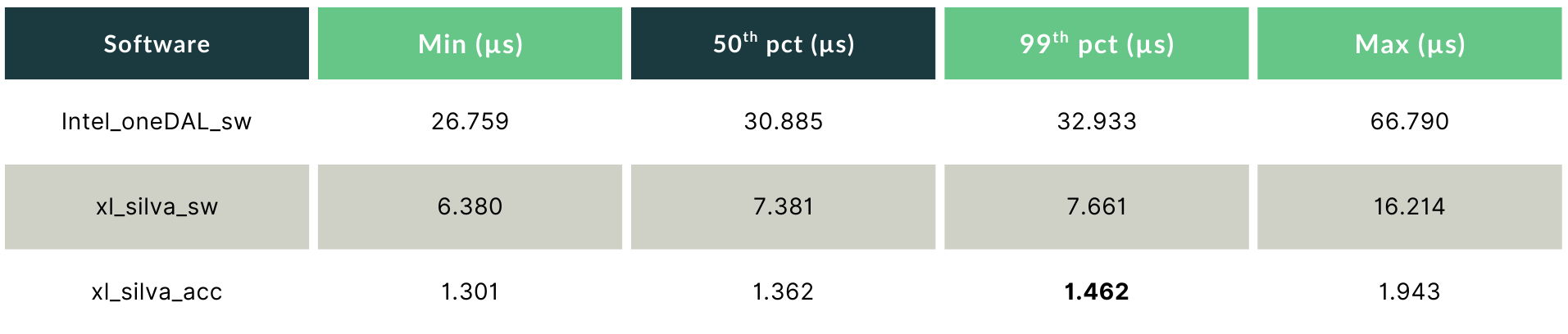
xl_silva_acc delivers a 99th percentile of 1.462 µs, 22.5× lower than Intel oneDAL, and 5.2× lower than xl_silva_sw. The min-to-99th spread is 0.161 µs. That 161-nanosecond envelope is the signature of hardware-governed execution: the FPGA’s latency is determined almost entirely by the model and the clock, with no measurable contribution from system-level variability.
Results: Multi-Model Concurrent Inference
Production HFT systems do not run a single model in isolation. They run several strategies simultaneously, each requiring its own inference call, each with its own latency SLA. The ability to scale horizontally without degrading tail latency is therefore as important as single-model speed.
8 Concurrent GBT_S Models

Both modes scale well for small models. xl_silva_sw holds sub-microsecond 99th percentile across all 8 concurrent instances, a strong result. However, its maximum spikes (up to 10.235 µs) are nearly 3× higher than xl_silva_acc’s (3.585 µs). Those spikes are the first visible sign of what the dedicated-execution argument predicts: when the CPU is handling 8 concurrent workloads, shared resource pressure begins to push the tail away from the median. For most controlled deployments this remains acceptable. But it is a signal worth watching as load grows.
4 Concurrent GBT_M Models
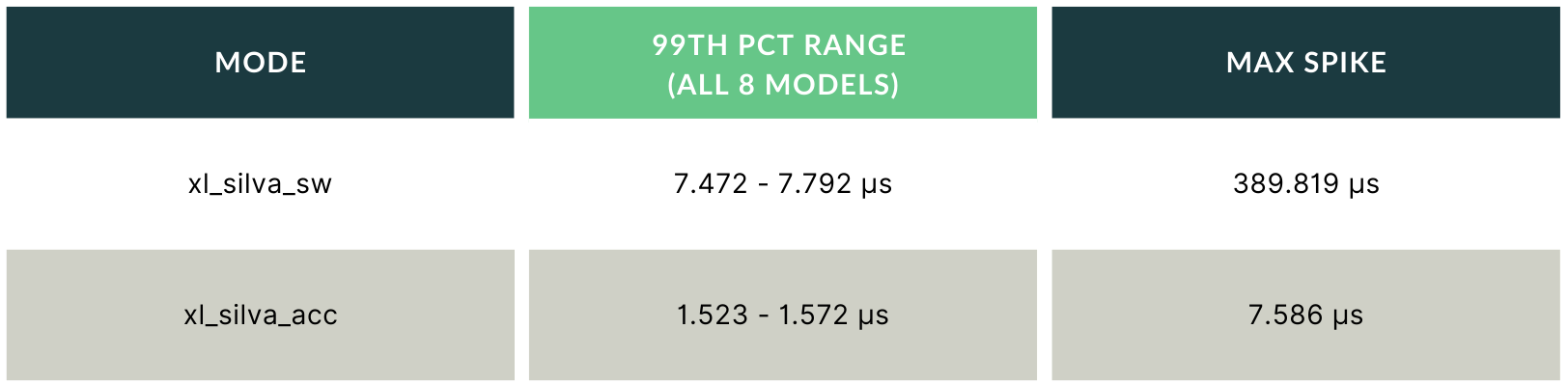
This is where the dedicated-execution architecture becomes a hard requirement. Under four concurrent GBT_M inference streams, xl_silva_sw produces maximum latency spikes reaching 389 µs, more than 200× the xl_silva_acc ceiling. This is CPU resource contention made visible: four processes competing for cache, memory bandwidth, and execution units produce a tail that is completely decoupled from the median.
A spike of that magnitude in a live trading system is not a performance issue; it is a risk event. It means your model did not score the signal. The order did not go out. The strategy misfired.
xl_silva_acc holds its 99th percentile within a 0.049 µs band across all four model instances, essentially matching the single-model baseline. That is determinism in practice: the tail does not grow as you add strategies, because each model instance runs on its own dedicated FPGA resources that no other process can disturb.
The Honest Tradeoff: Speed vs. Determinism
The two execution modes represent different answers to the same question: where does your workload hit its physical limits first?
xl_silva_sw trades some determinism for deployment flexibility. On small, cache-resident models in a controlled environment, the CPU path delivers near-deterministic sub-microsecond latency that rivals dedicated hardware. But it runs on shared silicon. As model size grows or concurrent load increases, the tail detaches from the median, measurably and unpredictably. You cannot bound the worst case, because you cannot control what else the host is doing.
xl_silva_acc trades the PCIe overhead for hardware-governed determinism. That fixed overhead (~0.55 µs round-trip) makes it slower than CPU-only for the smallest, fastest models. But for any model where inference time exceeds that threshold, the FPGA wins on every metric that matters in production: 99th percentile, maximum spike, inter-model consistency under concurrent load. And it wins by the same margin regardless of what else is running on the server, because each inference request runs on dedicated hardware resources and the host’s state is irrelevant to the execution time.
The choice is not about which execution mode is better. It is about whether your workload requires fast or guaranteed fast, and whether your models are small enough that the PCIe round-trip becomes the dominant cost.
Two Flavors. One Platform. One API.
Both execution modes are part of the same Xelera Silva product. Same C/C++ and Python API. Same integration path. No FPGA expertise required for either. Silva abstracts the hardware entirely.
Xelera Silva CPU-Only
• Sub-microsecond, near-deterministic 99th percentile for small, cache-resident models
• Runs on any machine or cloud, with no accelerator card and no specialised hardware
• Ideal for controlled environments where model size and concurrent load stay bounded
Xelera Silva Accelerator
• Hardware-governed, fully deterministic latency for medium-to-large models
• 99th percentile stays flat from 1 to 15 concurrent model instances; maximum spikes capped below 8 µs
• The right tool when worst-case latency must be guaranteed regardless of host system state
Full Benchmark Report
The complete benchmark report is available for download, including PCIe access latency, data transfer performance, CPU-only scaling results across GBT_S, GBT_M, and GBT_X, latency distribution graphs, and full test methodology.
All results were produced on real hardware under production-representative conditions. No synthetic workloads, no cherry-picked configurations.
Download the full Blackcore® ACE 3100-TS+ benchmark report
Xelera Technologies builds inference acceleration software for latency-critical applications. Xelera Silva supports LightGBM, XGBoost, and CatBoost models and is available for evaluation. Contact us at xelera.io.