GBT and LSTM models are on the critical execution path in production trading systems: scoring signals, ranking order flow, detecting anomalies. Whether the model produces alpha or arrives too late to act on it is determined by the execution layer, not by the model itself.
Most inference frameworks were built for batch or near-real-time workloads. On a latency-critical path, they run, but not at the speed a live strategy requires. A GBT with around 500 K-nodes on a standard CPU framework costs roughly 30 microseconds p99, and that figure rises under concurrent load. For LSTM models the gap is wider still.
Xelera Silva is built for this execution problem. It covers three deployment modes under a single API. The trained model file is the same across all three. Switching between modes is a single configuration parameter change.
Two model classes, two different execution problems
GBT and neural network models need different treatment at the hardware level, and understanding why clarifies how the three modes are structured.
GBT models (XGBoost, LightGBM, CatBoost) score by traversing a large number of decision trees. Each traversal follows a path determined by the input features, so memory access is irregular and branch-dependent. The processor cannot prefetch the next required memory location. The traversal bottleneck does not respond to the vectorisation techniques that work for matrix operations.
Neural networks (LSTM and others) perform dense matrix multiplications at each layer, with regular, predictable memory access. The challenge is supplying the parallel compute units with data fast enough to keep utilisation high.
An execution strategy tuned for one class leaves the other underserved. This reflects the hardware reality of how each model class uses memory and compute, and it cannot be resolved at the software level.
Three modes, one configuration parameter
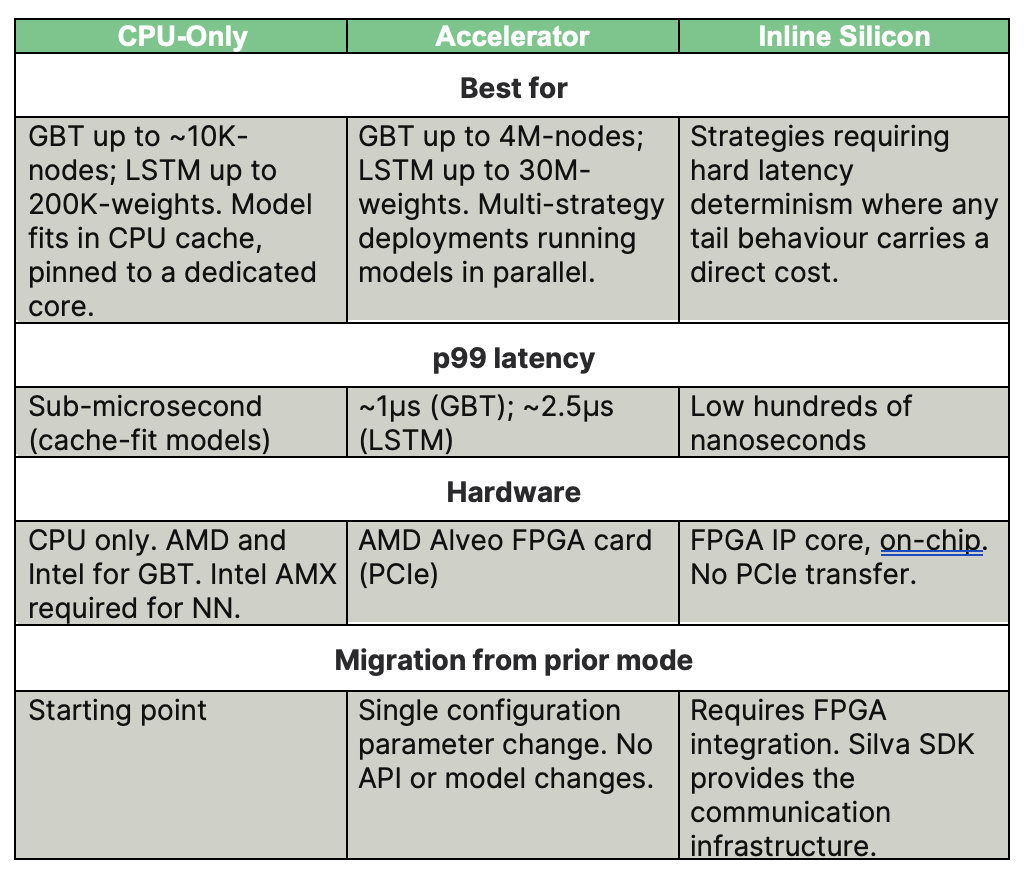
The table below summarises the three modes. The sections that follow explain each one in detail.
Mode 1: CPU-Only
Best for models up to roughly 10K-nodes (GBT) or 200K-weights (LSTM) that fit in CPU cache, pinned one-per-core
When a model fits entirely in CPU cache and runs on an isolated, dedicated core, Silva CPU-Only mode reaches sub-microsecond p99 latency with no additional hardware.
The cache-fit condition is what determines whether this holds. If the model overflows the cache, or workload from other processes pollutes cache state, p99 tails spike. Running multiple model instances is straight forward provided each one fits in cache and is pinned to its own core.
One hardware note: GBT models run in CPU-Only mode on both AMD and Intel platforms. NN models require Intel AMX.
Mode 2: Accelerator (FPGA Card)
Best for larger models and multi-strategy deployments running models in parallel
When models grow past the CPU cache-fit threshold, or when multiple strategies run concurrently, CPU-Only mode runs into contention. Accelerator mode moves inference to an AMD Alveo FPGA card, where each model runs as an independent pipeline in dedicated FPGA fabric. There is no shared resource pool.
The practical result is that p99 stays essentially flat as the number of concurrent model instances increases. Adding a strategy does not degrade the latency of those already running. This holds for both GBT and NN workloads.
Migration from CPU-Only mode is a single configuration parameter change. The API call is identical and the trained model file is the same. For teams whose model sizes have grown past the cache-fit threshold, or whose strategy count has increased to the point where CPU-Only tails are a problem, Accelerator mode is the natural upgrade path.
There is a latency cost from the PCIe data transfer between the host CPU and the FPGA. Mode 3 addresses this directly.
Mode 3: Inline Silicon (FPGA IP)
Best for strategies that require hard latency determinism
In Accelerator mode, data travels over PCIe between the host CPU and the FPGA card. That round-trip adds latency and, more significantly, adds variance. PCIe transfers are subject to bus arbitration and host-side scheduling overhead, neither of which is fully deterministic.
Inline Silicon mode removes the PCIe transfer from the path entirely. Inference runs as an IP core directly on the FPGA fabric. Market data enters on-chip and the inference result is produced on-chip. Latency is in the low hundreds of nanoseconds. Because the FPGA executes deterministically by construction, that latency does not vary with system load. Multiple models run as parallel pipelines with no arbitration between them.
This mode requires FPGA integration. Teams can build this themselves or use the Silva SDK, which provides the low-latency communication infrastructure covering both PCIe and Ethernet as the foundation. The inference IP core comes from Xelera; the surrounding FPGA design is the user's own.
Benchmark numbers
The following figures are from internal benchmarks with complete test conditions and hardware specifications available on request.
Accelerator mode vs standard CPU framework, p99 latency
GBT models
• ~10K-nodes: ~6µs on CPU → <1µs on Accelerator, ~7x faster
• ~500K-nodes: ~33µs on CPU → ~1µs on Accelerator, ~25x faster
LSTM models
• 200K-nodes: <1.9µs p99 on Accelerator, 66x below CPU baseline
• 1M-nodes: <2.5µs p99 on Accelerator, 86x below CPU baseline
Concurrency
• p99 increase from NMI 1 to NMI 8: less than 2%
For a model-specific benchmark assessment: xelera.io/silva
Deployment
Silva accepts models trained with existing pipelines. XGBoost, LightGBM, CatBoost, and LSTM models are all supported. The C, C++, C# and Python API is unified across all three modes. Models can be hot-swapped without restarting the host process. The runtime is thread-safe and process-safe for concurrent strategy deployments.
A 30-day evaluation period is available and includes a model-specific performance assessment. To request a benchmarking session: xelera.io/silva.
Next steps
Request a model-specific benchmark assessment.
Contact Xelera at info@xelera.io or visit xelera.io/silva. The evaluation runs on your own trained model weights and feature distributions. A 30-day trial period is available.
Read the STAC-ML El Popo benchmark results.
The first independently audited STAC-ML El Popo submission, configuration XLRA260312, measures Accelerator mode performance on GBT topologies at production scale. Results are available in the STAC Vault at stacresearch.com.
Contact
- Xelera Technologies: info@xelera.io | xelera.io/silva
- AMD for Financial Services: amd.com/en/solutions/financial-services.html
- STAC Vault: stacresearch.com/XLRA260312 (STAC Vault membership required)