In time-critical systems, speed is a competitive advantage—and jitter can be fatal. High-frequency trading (HFT) and in-path network analytics rely on split-second, data-driven decisions where every microsecond counts.
Xelera Silva is an ultra-low latency inference accelerator that brings deterministic, production-ready performance to real-time machine learning pipelines—without forcing teams to rewrite their models. Silva is built for drop-in integration: teams keep their training workflow and model logic; integration focuses on connecting either the offload API or inline data-path.
What is Xelera Silva?
Silva accelerates inference for tree-based machine learning models—especially gradient-boosted decision trees (e.g., XGBoost, LightGBM, CatBoost) – and Neural Networks (e.g., LSTM), using transparent FPGA-based hardware acceleration.
Silva can be deployed in two ways:
• Offload Mode (PCIe-attached accelerator): The host application calls a C/C++/C# or Python API to submit a feature vector (batch size = 1) to the FPGA accelerator card and receives a prediction back with microsecond-class latency.
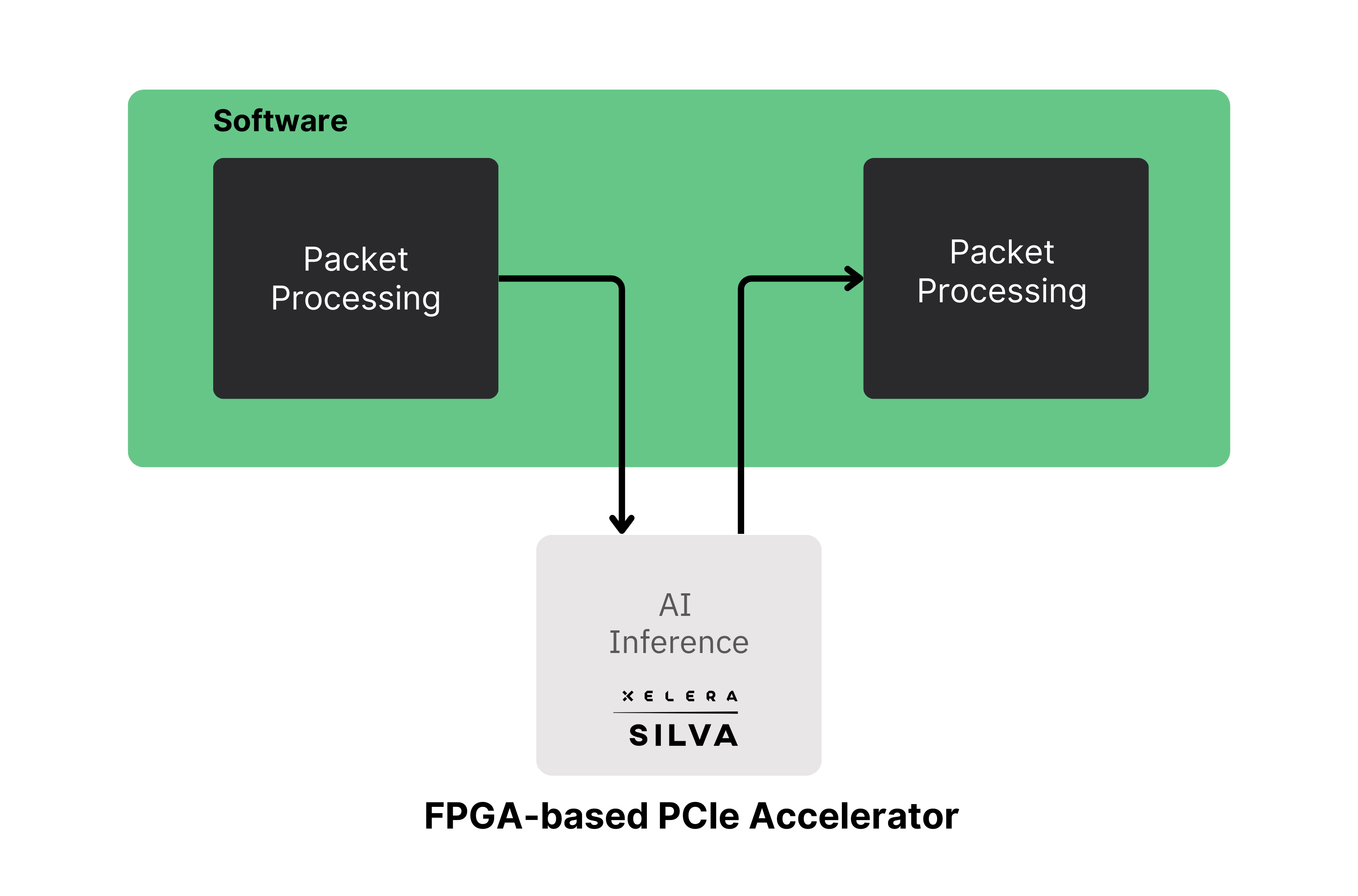
• Inline Mode (SmartNIC datapath): The Silva FPGA IP is integrated directly into an FPGA-based SmartNIC datapath so inference runs on streaming data (packets, events, or market feeds) without host involvement on the critical path – bypassing the transfer over the PCIe bus and providing sub-microsecond inference latency.
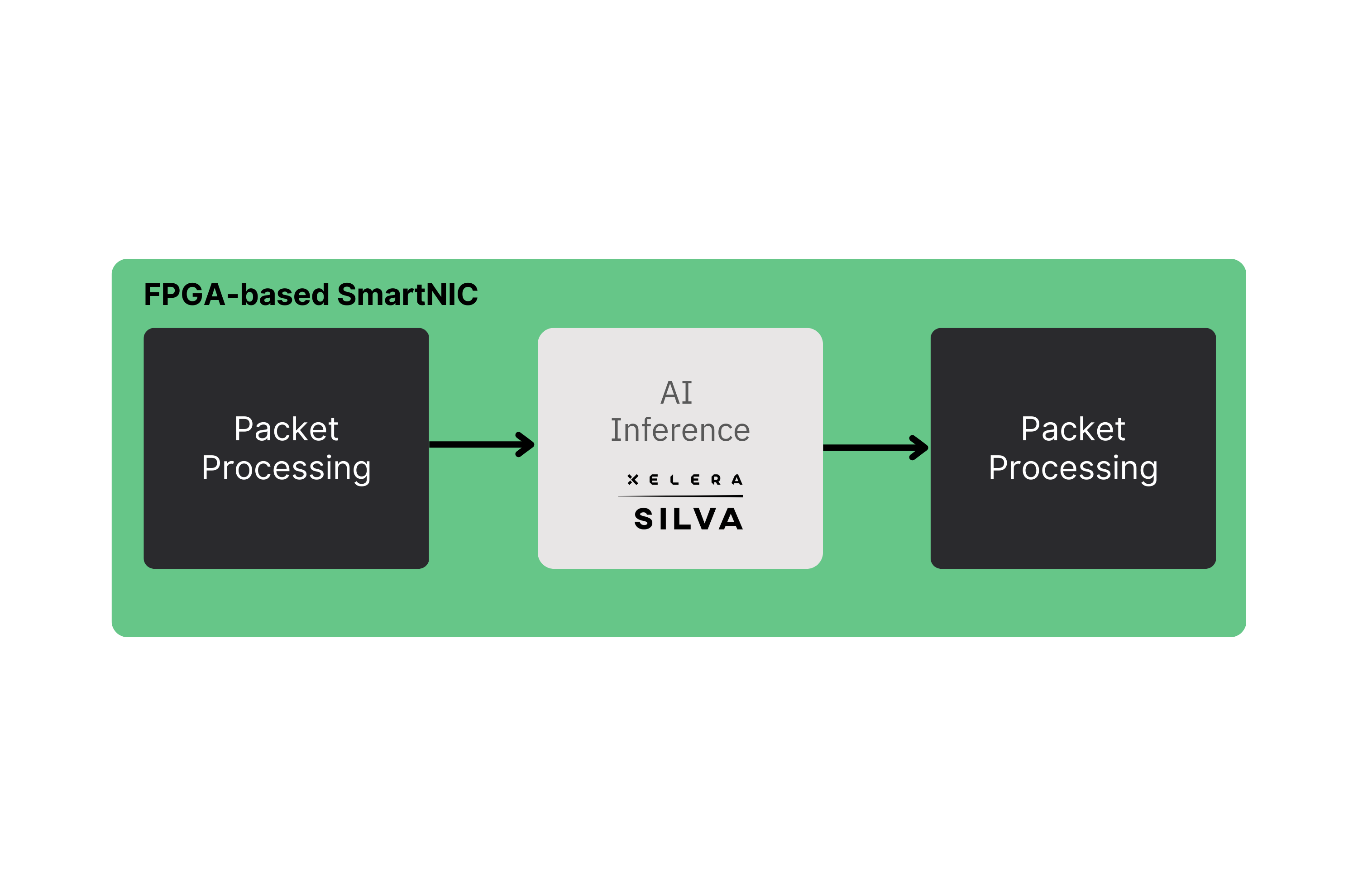
This two-tier deployment path lets teams start with the fastest integration option and later upgrade to the lowest possible end-to-end latency when requirements tighten.
Why use Xelera Silva?
Silva delivers ultra-low inference latency and predictability critical production environments where performance matters. It delivers three core advantages: speed, consistency, and ease of use.
1) Speed: Ultra-low latency inference
When nanoseconds/microseconds can translate into real revenue or risk reduction, inference latency becomes a first-order design constraint.
In the Offload Mode, Silva typically delivers single-request inference (batch size = 1) in the single-microsecond range — significantly faster than any CPU-based approach which can take tens of microseconds depending on the model, CPU, and runtime stack, and may introduce substantial jitter.
For gradient-boosted tree models, Silva typically delivers 1.0 to 1.4 microseconds in the Offload Mode. For a typical 512K-node, 128 features LightGBM model, Silva has shown a median inference latency of 1.136 microseconds.
See benchmark reports:
Blackcore
• Blackcore ICON 3100-RL+ Server
• Blackcore ACE 3100-RZ Server
Napatech:
International Computer Concepts (ICC)
To achieve the lowest possible latency, the Inline Mode can reduce end-to-end inference to the sub-microsecond range (for example, ~400 nanoseconds depending on integration) by eliminating the PCIe transfer overhead and host involvement on the critical path.
Note: Latency figures reflect single-request inference (batch size = 1). End-to-end and p99 performance depend on model size, integration choices, and surrounding pipeline stages.
2) Consistency: Eliminates latency spikes (low jitter)
Beyond low average latency, Silva is built to deliver deterministic performance—results that are not only fast, but predictable.
In Offload Mode, Silva eliminates CPU scheduling and cache effects that commonly cause latency spikes. Through a vertically integrated design spanning the API, driver, ultra-low-latency PCIe DMA, and FPGA inference kernel, Silva delivers—for example—a 99th-percentile latency of 1.179 microseconds for a typical LightGBM model with 512K nodes and 128 features.
In Inline Mode, inference runs as a fully hardware-timed pipeline inside the SmartNIC datapath. Because FPGA execution is deterministic and does not depend on OS scheduling or shared CPU resources, inline deployments can dramatically reduce inference-engine jitter—ideal for hard real-time pipelines such as tick-to-trade HFT and in-path packet inspection.
3) Ease of use: Fast integration with a clear upgrade path
Silva is a drop-in inference solution: customers bring their own trained model, and Silva accelerates it without requiring changes to the model itself.
Start quickly with software integration (Offload Mode)
Most teams begin with the Offload Mode using the high-performance software API.
• Quick start: minimal code changes, familiar language bindings, and fast time-to-value for existing software pipelines.
• Best for: teams that want acceleration quickly while keeping inference orchestration in the host application.
Upgrade to inline deployment (lowest end-to-end latency)
When end-to-end latency requirements become more stringent, Silva can be deployed inline by integrating the Silva FPGA IP directly into an FPGA-based SmartNIC datapath. In this mode, inference runs on streaming data in-path—avoiding host involvement on the critical path.
• Quick start: the Silva FPGA IP is validated and compatible across major FPGA devices, providing a portable building block for inline deployments.
• Best for: in-path network analytics/security and ultra-low latency HFT “tick-to-trade” pipelines where decisions must be made directly on the data stream.
Primary use cases
Silva is broadly applicable wherever decisions must be made on live data streams, and it is especially impactful in industries defined by speed.
High-frequency trading (HFT) and algorithmic trading
• Real-time trade execution: Run AI-driven strategies (e.g., boosted-tree models) fast enough to act within stringent exchange and market microstructure constraints.
• Market data processing: Accelerate analysis of high-volume market data feeds for faster signal generation.
Network analytics, cybersecurity, and fraud detection
• Instantaneous threat detection: Apply models to packet/flow inspection and transaction patterns fast enough to respond in real time.
• Next-generation firewalls: Accelerate compute-intensive ML-based security functions for high-throughput network connections.
The future is fast
Silva represents a leap forward in deploying AI where every microsecond counts. By enabling deterministic, sub-microsecond-class inference in production, Silva helps organizations deliver real-time decisions across finance, network security, and beyond.
Want to see Silva on your model and pipeline? Contact Xelera via sales@xelera.io to request benchmark reports and an integration walkthrough.